Der perfekte Kubernetes Production Cluster mit Hetzner Dedicated Server, Proxmox VE, K3S und BGP
Einleitung
Wie wir bereits im Artikel Kubernetes Preisvergleich festgestellt haben, bietet Hetzner ein exzellentes Preis-Leistungs-Verhältnis für Kubernetes-Cluster. Die Kombination aus leistungsfähiger Hardware und attraktiven Preisen macht Hetzner zu einer idealen Wahl für produktive Umgebungen.
In diesem Beitrag zeigen wir euch, wie wir auf den Dedicated Servern von Hetzner einen stabilen und skalierbaren Kubernetes-Cluster einrichten können. Dabei gehen wir Schritt für Schritt durch alle notwendigen Konfigurationen und Best Practices – vom Server-Setup bis hin zur Bereitstellung von Anwendungen. Wir werden folgende Themen abdecken:
- Vorbereitungen und Anforderungen – Welche Voraussetzungen sollten erfüllt sein, und wie wählen wir die richtige Serverkonfiguration?
- Installation von Proxmox – Eine detaillierte Anleitung zur Installation und Konfiguration von Proxmox auf den Hetzner-Servern.
- Konfiguration von Proxmox – Wie wir den Proxmox Cluster für unseren Kubernetes Cluster perfekt vorbereiten.
- Installation von Kubernetes – Eine detaillierte Anleitung zur Installation und Konfiguration von Kubernetes auf den Hetzner-Servern.
- Konfiguration von Kubernetes – Die Konfiguration unseres Kubernetes Clusters.
Lasst uns gemeinsam den gesamten Prozess durchlaufen, damit euer Kubernetes-Cluster auf Hetzner bereit für den produktiven Einsatz ist!
Vorbereitungen und Anforderungen
Um einen produktiven Kubernetes-Cluster auf Hetzner aufzubauen, benötigen wir mindestens drei Dedicated Server, die idealerweise über die folgende Ausstattung verfügen.
Für die gesamte Infrastruktur:
- (Optional) 12-Port-10G-Switch: Ein solcher Switch wird benötigt, wenn wir ein dediziertes 10G-Netzwerk für unseren Cluster planen. Somit können wir 10G Bandbreite für Ceph und 10G Bandbreite für unser SDN bereitstellen. Der Netzwerk-Uplink sollte auch über den Switch erfolgen.
- (Optional) 8-Port-1G-Switch: Über diesen Switch können wir die Cluster-Kommunikation für Proxmox vornehmen.
Pro Node:
- Sollten im gleichen Rack bereitgestellt werden
- (Optional) Benötigen (vorerst) keine öffentliche IPv4 Adressen
- Mindestens 2x zusätzliche Festplatten: Diese sind optional, aber für die Nutzung eines verteilten Speichersystems wie Ceph erforderlich. Alternativ kann auch lokaler LVM-Storage verwendet werden.
- (Optional) Intel X520-DA2 mit mindestens 2x 10G-Schnittstellen: Beide 10G Uplinks mit dem 10G Switch verbinden.
- (Optional) OnBoard NIC 1G: Alle Server mit 1G Switch verbinden
Die zusätzlichen Optionen sollten während der Bestellung im Bemerkungsfeld angegeben werden, da es sich hierbei nicht um eine Standardbestellung handelt. Ein Hetzner-Datacenter-Techniker wird diese speziellen Anforderungen individuell bearbeiten.
Eine kostengünstige Beispielkonfiguration könnte wie folgt aussehen. Beachte, dass du natürlich selbst entscheiden kannst, welches System am besten zu deinen Anforderungen passt.
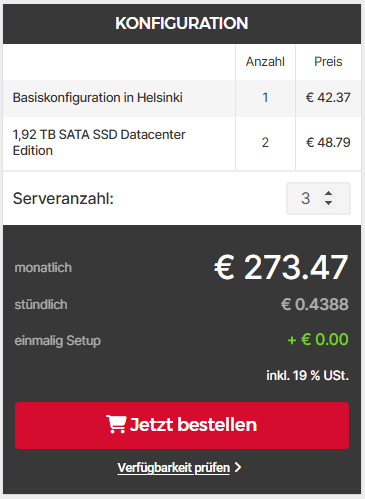
Hinweis: Nach der Installation der Hardware empfiehlt es sich, die kostenlosen Storage-Boxen BX10 für die Server zu aktivieren und darauf SAMBA/CIFS einzurichten. Diese zusätzlichen Speicherlösungen eignen sich hervorragend, um Images und Backups sicher extern zu speichern. Für den direkten Einsatz als VM- oder Container-Diskspeicher sind sie jedoch aufgrund von Leistungs- und Latenzbeschränkungen weniger empfehlenswert.
Installation von Proxmox
Die einzelnen Server sind nun bereitgestellt und entweder über eine öffentliche IPv4- oder IPv6-Adresse per SSH erreichbar. Aktuell befinden wir uns im Hetzner Rescue-System, einem Linux-basierten System, das über PXE gebootet wird. Dieses Rescue-System ermöglicht es uns, grundlegende Wartungsarbeiten durchzuführen, wie beispielsweise das Mounten der Server-Disks. Zudem können wir über den Befehl chroot in das Dateisystem des Servers wechseln, um Konfigurationen oder Reparaturen direkt am installierten Betriebssystem vorzunehmen. Mehr zu dem Hetzner Rescue-System hier.
Wir werden das Proxmox-on-Debian-Bookworm-Image mithilfe des Tools installimage installieren und dabei das Betriebssystem nach unseren Anforderungen konfigurieren. Achte darauf, die Konfiguration entsprechend deiner Infrastruktur anzupassen – dies betrifft insbesondere die Festplatteneinstellungen, das Software-RAID und das LVM-Setup. Passe die Partitionierung und Speicherstruktur so an, dass sie optimal zu deinem Setup und den spezifischen Anforderungen deiner Serverumgebung passen.
Achte darauf, dass der Hostname ein eindeutiger FQDN (Fully Qualified Domain Name) ist, also eine vollständige Domain, die auf die öffentliche IPv4- oder IPv6-Adresse verweist und von außen erreichbar ist. Andernfalls kann es zu Problemen im Proxmox-Cluster kommen, da dieser auf die Erreichbarkeit der Hostnamen angewiesen ist. Es empfiehlt sich außerdem, alle Systeme im Cluster in der Datei /etc/hosts zu hinterlegen, um eine stabile Namensauflösung innerhalb des Netzwerks zu gewährleisten.
Du kannst einzelne Festplatten mithilfe des Symbols # von der Konfiguration ausschließen, was besonders für den Einsatz mit Ceph empfohlen wird. Wenn du hingegen nur ein Local-LVM verwenden möchtest, kannst du diese Festplatten in die Konfiguration aufnehmen. Du hast außerdem die Flexibilität, selbst zu entscheiden, ob du die NVMe-SSDs für Ceph oder für den lokalen Speicher nutzen möchtest. Diese Einstellungen sind anpassbar und sollten entsprechend deinen Anforderungen und der gewünschten Speicherarchitektur vorgenommen werden.
DRIVE 1 /dev/sda
DRIVE 2 /dev/sda
#DRIVE 3 /dev/sdb
#DRIVE 3 /dev/sdc
SWRAID 1
SWRAIDLEVEL 1
BOOTLOADER grub
HOSTNAME proxmox0[1-3].[deinedomain]
PART /boot ext3 2G
PART lvm proxmox all
LV proxmox root / ext4 50G
LV proxmox swap swap swap 16G
LV proxmox home /home xfs 15G
LV proxmox opt /opt xfs 15G
LV proxmox var /var xfs 50G
IMAGE /root/images/Debian-bookworm-latest-amd64-base.tar.gz
Nachdem der Server erfolgreich installiert wurde und Proxmox gebootet ist, können wir mit der Konfiguration der Proxmox-Infrastruktur fortfahren. In den nächsten Schritten richten wir die Netzwerkparameter, die Cluster-Einstellungen sowie die Speicher- und Backup-Optionen ein, um eine stabile und skalierbare Umgebung für unsere Virtualisierungs- und Container-Workloads zu schaffen.
Konfiguration von Proxmox
Hetzner vSwitch
Für die weitere Konfiguration wechseln wir erneut in den Hetzner Robot und richten dort einen vSwitch ein. Dieser befindet sich auf der Übersichtsseite der Dedicated Server. Wir wählen einen Namen sowie eine VLAN-ID aus; in diesem Beispiel verwenden wir die VLAN-ID 4000 und fügen alle unsere Server in den vSwitch ein.
Im nächsten Schritt konfigurieren wir den vSwitch in der Datei /etc/network/interfaces. Achte darauf, dass sich die Namen deiner Netzwerkinterfaces sowie die IP-Adressen je nach Serverkonfiguration unterscheiden können. Passe die Konfiguration daher an deine spezifischen Netzwerkdetails an.
auto lo
iface lo inet loopback
iface lo inet6 loopback
auto enp35s0
iface enp35s0 inet static
address [SERVER IPv4 ADDRESS CIDR]
gateway [SERVER IPv4 GATEWAY]
# Public Network v4
iface enp35s0 inet6 static
address [SERVER IPv6 ADDRESS CIDR]
gateway fe80::1
# Public Network v6
auto enp35s0.4000
iface enp35s0.4000 inet manual
# vSwitch VLAN
auto vmbr4000
iface vmbr4000 inet static
address 10.0.1.2/24 # 10.0.1.2 für proxmox01, 10.0.1.3 für proxmox02 und 10.0.1.4 für proxmox03
bridge-ports enp35s0.4000
bridge-stp off
bridge-fd 0
mtu 1400
up route add -net 10.0.0.0 netmask 255.255.0.0 gw 10.0.1.1 dev vmbr4000
post-up iptables -t nat -A POSTROUTING -s '10.0.1.0/24' -o enp35s0 -j MASQUERADE
post-down iptables -t nat -D POSTROUTING -s '10.0.1.0/24' -o enp35s0 -j MASQUERADE
# vSwitch vmbr4000
source /etc/network/interfaces.d/*
In dieser Netzwerk-Konfiguration richten wir zudem NAT ein, sodass VMs im vmbr4000-Netzwerk über das Internet kommunizieren können. Da unsere Kubernetes-Nodes keine öffentlichen IPv4-Adressen benötigen, reicht es aus, ihnen den Zugriff auf das Internet über NAT bereitzustellen.
Die Server sollten nun über die IPv4 Adressen erreichbar sein:
ping 10.0.1.3
ping 10.0.1.4
Zusätzlich besteht die Möglichkeit, den vSwitch bei Bedarf mit unseren Hetzner Cloud VMs zu verknüpfen. Dadurch können wir eine nahtlose Verbindung zwischen den Dedicated Servern und den Cloud-Instanzen herstellen, was besonders nützlich ist, wenn Kubernetes-Cluster über mehrere Umgebungen hinweg skaliert werden sollen oder zusätzliche Ressourcen aus der Cloud eingebunden werden. Diese Verknüpfung ermöglicht eine flexible, hybride Infrastruktur, in der sowohl Dedicated Server als auch Cloud-Ressourcen effizient in einem gemeinsamen Netzwerk arbeiten.
Proxmox Cluster
Da die Systeme nun miteinander kommunizieren können, stelle sicher, dass alle Server in der Datei /etc/hosts eingetragen sind. Verwende dafür die IP-Adressen aus dem 10.0.1.0/24-Bereich, da wir über dieses Subnetz die Cluster-Kommunikation aufbauen möchten.
Auf dem Server proxmox01 gehen wir zu Datacenter -> Cluster -> Create Cluster und wählen als Cluster-Netzwerk unser 1G-Netzwerk aus.
Auf den Servern proxmox02 und proxmox03 verwenden wir die Join Information, um dem Cluster beizutreten. Achte dabei darauf, immer das richtige Cluster-Netzwerk auszuwählen, um eine stabile und einheitliche Verbindung im gesamten Cluster sicherzustellen.
Proxmox SDN
Um das Proxmox Software Defined Networking (SDN) zu aktivieren, müssen wir zunächst einige zusätzliche Pakete installieren, die in der Standard-Proxmox-Installation nicht enthalten sind. Diese Pakete erweitern die Netzwerkkapazitäten und erlauben die Konfiguration von SDN-Features
apt -y update
apt -y install libpve-network-perl frr-pythontools
Damit haben wir nun die Grundlage geschaffen, das Software-Defined Network (SDN) direkt über die Proxmox-Oberfläche weiter zu konfigurieren. So können wir Netzwerkressourcen zentral verwalten, virtuelle Netzwerke einrichten und nahtlos auf die erweiterten SDN-Funktionen zugreifen, um den Netzwerkverkehr flexibel und effizient zu steuern.
Als nächsten Schritt wechseln wir in die Proxmox-Oberfläche und navigieren zu Datacenter -> SDN -> Options, um dort einen evpn-Controller zu erstellen. Dieser evpn-Controller ermöglicht die Nutzung eines Ethernet VPNs innerhalb der SDN-Umgebung, wodurch virtuelle Netzwerke effizient über mehrere Hosts hinweg verwaltet und verteilt werden können.
- ASN: Wert
65000belassen. - Peers: Dort werden alle Proxmox Nodes eingetragen und alle Kubernetes Master Nodes (ich nutze hier den Bereich
10.0.2.21 - 10.0.2.23für meine Kubernetes Master). Beispiel-Wert:10.0.1.2,10.0.1.3,10.0.1.4,10.0.2.21,10.0.2.22,10.0.2.23.
Als nächsten Schritt navigieren wir zu Datacenter -> SDN -> Zones und erstellen eine EVPN-Zone. Hier sind einige Beispielwerte für die Konfiguration:
- ID:
vnet - Controller: den vorher erstellten
bgp - VRF-VXLAN Tag:
4005 - Exit Nodes:
proxmox01, proxmox02, proxmox03 - Primary Exit Node:
proxmox01 - Exit Nodes Local Routing:
Nein - Advertise Subnets:
Ja - Disable ARP-nd Suppression:
Ja - MTU
1400
Alle weiteren Einstellungen können unverändert bleiben oder bei Bedarf an deine spezifischen Anforderungen angepasst werden. So hast du die Flexibilität, die EVPN-Zone optimal auf die Bedürfnisse deines Netzwerks und Workloads abzustimmen.
Diese Konfiguration ermöglicht eine effiziente Verteilung des Netzwerks über die definierten Knoten und stellt sicher, dass die EVPN-Zone als logisches Netzwerk im gesamten Proxmox-Cluster verfügbar ist. Dadurch können die Kubernetes-Nodes und Proxmox die verwendeten IP-Adressen nahtlos miteinander austauschen, was eine reibungslose Kommunikation und Verwaltung der Netzwerkressourcen innerhalb des Clusters gewährleistet.
Proxmox Storage
Falls ihr Ceph verwenden möchtet, könnt ihr die Installation einfach über die Proxmox-Oberfläche unter Datacenter -> Ceph durchführen. Nach der Installation lassen sich die OSDs und weitere Ceph-Komponenten flexibel konfigurieren und einrichten. Eine detaillierte Anleitung zur kompletten Ceph-Konfiguration würde jedoch den Rahmen dieses Artikels sprengen.
Ich nutze zusätzlich die kostenlosen Storage-Boxen als externen Speicher. Diese bieten eine kosteneffiziente Möglichkeit, Backups, Images und andere wichtige Daten sicher und außerhalb des Hauptservers zu speichern.
Darüber hinaus sollte auch der local-lvm-Speicher angelegt werden. Dazu wählt ihr die Volume Group proxmox aus. Dieser Speicherbereich kann nun für VMs genutzt werden und dient als zusätzlicher Speicherplatz, der bei der Installation noch nicht definiert wurde.
Debian Cloud Image
Um ein Debian Cloud Image für unsere Kubernetes-Nodes bereitzustellen, könnt ihr die folgenden Befehle verwenden:
cd /var/lib/vz/images
wget https://cloud.debian.org/images/cloud/bookworm/latest/debian-12-generic-amd64.qcow2
qm create 9000 --memory 4096 --net0 virtio,bridge=vmbr4000 --scsihw virtio-scsi-pci
qm set 9000 --scsi0 local-lvm:0,import-from=/var/lib/vz/images/debian-12-generic-amd64.qcow2
qm set 9000 --ide2 local-lvm:cloudinit
qm set 9000 --boot order=scsi0
qm set 9000 --serial0 socket --vga serial0
qm template 9000
Dieser Prozess lädt das aktuelle Debian-Cloud-Image für “Bookworm” herunter und erstellt eine Vorlage (template) für die Kubernetes-Nodes mit 4 GB RAM und einer Netzwerkschnittstelle, die über vmbr4000 kommuniziert. Anschließend wird das Image als scsi0 eingebunden und das cloudinit-Laufwerk eingerichtet, um eine Cloud-Init-Konfiguration zu ermöglichen. Mit diesen Einstellungen steht das Image als VM-Vorlage bereit und kann für den schnellen Start weiterer Kubernetes-Nodes genutzt werden.
Installation von Kubernetes
Nun erstellen wir auf jedem unserer Server basierend auf dem Debian Cloud Image jeweils einen Master-Node und einen Worker-Node für den Kubernetes-Cluster. Für die Master-Nodes nutzen wir die IP-Range 10.0.2.21 - 10.0.2.23. Die IP-Adresse 10.0.2.20 wird als Cluster VIP (Virtual IP) reserviert und bleibt frei, um eine hochverfügbare Cluster-Verwaltung zu ermöglichen. Die Worker-Nodes verwenden die IP-Range 10.0.2.31 - 10.0.2.33.
Diese Konfiguration stellt sicher, dass die Master- und Worker-Nodes über dedizierte IP-Adressen kommunizieren können und die Cluster VIP zur Verfügung steht, um den Cluster stabil zu halten und automatisch auf einen anderen Master-Node umzuschalten, falls dies erforderlich ist.
Mit dem in Proxmox integrierten Cloud-Init-Tool können wir grundlegende Einstellungen wie Hostname, Benutzername, SSH-Keys, IP-Konfiguration und mehr direkt an die VM übergeben. Dadurch wird die Ersteinrichtung der VM automatisiert und es sind keine zusätzlichen manuellen Konfigurationen erforderlich. Cloud-Init erleichtert die Verwaltung und Anpassung der Kubernetes-Nodes, sodass sie sofort einsatzbereit sind.
Ich verwende das Tool k3sup, das es mir ermöglicht, auf einfache Weise und direkt von meinem lokalen PC aus einen Kubernetes-Cluster zu erstellen. Mit k3sup lassen sich Kubernetes-Installationen automatisieren und die Knoten schnell verbinden, was den Aufbau eines Clusters erheblich vereinfacht.
k3sup install --ip 10.0.2.21 --tls-san 10.0.2.20 --cluster --k3s-channel latest --k3s-extra-args "--disable servicelb" --local-path $HOME/.kube/config --user kube
Sobald der erste Master-Node bereit ist, installieren wir kube-vip, um die Hochverfügbarkeit des Clusters zu gewährleisten. Zunächst benötigen wir die RBAC-Datei (Role-Based Access Control), um die erforderlichen Berechtigungen für kube-vip festzulegen. Anschließend erstellen wir die Konfigurationsdatei, die die Einstellungen für den VIP (Virtual IP) und die Kommunikation zwischen den Master-Nodes enthält.
Alle folgenden Befehle werden auf unserem Kubernetes-Master-Node 01 (10.0.2.21) ausgeführt:
kubectl apply -f https://kube-vip.io/manifests/rbac.yaml
export VIP=10.0.2.20
export INTERFACE=lo
KVVERSION=$(curl -sL https://api.github.com/repos/kube-vip/kube-vip/releases | jq -r ".[0].name")
alias kube-vip="ctr image pull ghcr.io/kube-vip/kube-vip:$KVVERSION; ctr run --rm --net-host ghcr.io/kube-vip/kube-vip:$KVVERSION vip /kube-vip"
kube-vip manifest daemonset \
--interface $INTERFACE \
--address $VIP \
--inCluster \
--taint \
--controlplane \
--services \
--bgp \
--localAS 65000 \
--bgpRouterID 10.0.2.20 \
--bgppeers 10.0.1.2:65000::false,10.0.1.3:65000::false,10.0.1.4:65000::false | tee /var/lib/rancher/k3s/server/manifests/kube-vip.yaml
In der Option bgppeers haben wir unsere Proxmox-Nodes hinterlegt. Dadurch kann der Kubernetes-Cluster direkt mitteilen, welche VIPs (Virtual IPs) über BGP (Border Gateway Protocol) angekündigt werden sollen. Diese Konfiguration sorgt dafür, dass die VIPs automatisch über das Netzwerk verteilt werden und die Proxmox-Nodes stets wissen, welche IPs aktiv im Cluster verwendet werden. Dies erhöht die Ausfallsicherheit und verbessert die Netzwerkkommunikation im Cluster erheblich.
Nun fügen wir die restlichen Master-Nodes mit k3sup hinzu:
k3sup join --ip 10.0.2.22 --server-ip 10.0.2.20 --server --k3s-channel latest --user kube
k3sup join --ip 10.0.2.23 --server-ip 10.0.2.20 --server --k3s-channel latest --user kube
Anschließend fügen wir die Worker-Nodes hinzu:
k3sup join --ip 10.0.2.31 --server-ip 10.0.2.20 --k3s-channel latest --user kube
k3sup join --ip 10.0.2.32 --server-ip 10.0.2.20 --k3s-channel latest --user kube
k3sup join --ip 10.0.2.33 --server-ip 10.0.2.20 --k3s-channel latest --user kube
Diese Befehle verbinden die zusätzlichen Master- und Worker-Nodes nahtlos mit dem Cluster, wobei die Cluster-Kommunikation über die VIP 10.0.2.20 läuft. So wird die Hochverfügbarkeit gewährleistet, da die Master-Nodes miteinander synchronisiert werden und die Worker-Nodes ihre Anweisungen zentral über den Cluster erhalten.
Mit dem Befehl kubectl get nodes lässt sich überprüfen, ob alle Knoten erfolgreich dem Cluster beigetreten sind und korrekt arbeiten. Dieser Befehl zeigt eine Liste aller Master- und Worker-Nodes an und gibt ihren aktuellen Status sowie ihre Rollen im Cluster an. So können wir sicherstellen, dass die Clusterstruktur vollständig ist und alle Verbindungen korrekt hergestellt wurden.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
km1 Ready control-plane,etcd,master 2d19h v1.31.2+k3s1
km2 Ready control-plane,etcd,master 2d19h v1.31.2+k3s1
km3 Ready control-plane,etcd,master 2d19h v1.31.2+k3s1
kw1 Ready <none> 4h45m v1.30.6+k3s1
kw2 Ready <none> 2d18h v1.30.6+k3s1
kw3 Ready <none> 4h45m v1.30.6+k3s1
Die Kubernetes-Installation ist damit abgeschlossen. Alle Knoten sind erfolgreich dem Cluster beigetreten und die grundlegende Konfiguration ist eingerichtet. Der Cluster ist nun einsatzbereit für das Deployment von Anwendungen und die Verwaltung über kubectl.
Konfiguration von Kubernetes
Um LoadBalancer in Kubernetes nutzen zu können, installieren wir zunächst den kube-vip Cloud Controller mit folgendem Befehl:
kubectl apply -f https://raw.githubusercontent.com/kube-vip/kube-vip-cloud-provider/main/manifest/kube-vip-cloud-controller.yaml
Zusätzlich erstellen oder bearbeiten wir eine ConfigMap, um den IP-Bereich für die VIPs (Virtual IPs) festzulegen. In diesem Beispiel verwenden wir den Bereich 10.0.2.200-10.0.2.240:
kubectl create configmap -n kube-system kubevip --from-literal range-global=10.0.2.200-10.0.2.240
Mit dieser Konfiguration können LoadBalancer-Dienste im Kubernetes-Cluster automatisch VIPs aus dem definierten IP-Bereich beziehen und so den externen Zugriff auf Anwendungen ermöglichen. Wir können in der ConfigMap auch öffentliche IP-Adressen aus Failover-Subnetzen eintragen, die wir über den vSwitch gebucht haben. Durch die Integration mit dem SDN und die Nutzung von BGP werden diese IP-Adressen korrekt im Netzwerk geroutet, sodass externe Zugriffe über LoadBalancer-Dienste im Kubernetes-Cluster möglich sind. Diese Flexibilität ermöglicht es uns, VIPs sowohl für interne als auch für öffentliche Dienste zu nutzen und dabei eine zuverlässige Netzwerkstruktur zu gewährleisten.
Wenn wir den mit k3s mitgelieferten Traefik als Ingress verwenden möchten, müssen wir diesen anpassen:
kubectl edit service traefik -n kube-system
Anschließend ändern wir in der Konfiguration des Traefik-Ingress den Wert spec.loadBalancerIP und tragen die öffentliche IP-Adresse ein, über die der Ingress erreichbar sein soll. Damit wird der Traefik-Ingress öffentlich verfügbar und kann extern angesprochen werden.
Dank dieser Einstellung können wir in Kombination mit dem cert-manager automatisch SSL-Zertifikate erstellen und verwalten. Dadurch wird das Deployment von Anwendungen deutlich erleichtert, da HTTPS-Verbindungen zentral und automatisiert abgesichert sind, und die Verwaltung von Zertifikaten erfolgt gebündelt im Cluster.
Tests
Mit diesem Beispiel-Deployment können wir testen, ob die Konfiguration wie gewünscht funktioniert.
Die Datei whoami.yaml definiert ein ReplicaSet mit drei Replikaten der whoami-Anwendung, einen Service zur Bereitstellung der Anwendung und einen Ingress, um die Anwendung extern verfügbar zu machen:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: whoami
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: traefik/whoami
---
apiVersion: v1
kind: Service
metadata:
name: whoami
namespace: default
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
app: whoami
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: whoami
namespace: default
annotations:
cert-manager.io/cluster-issuer: letsencrypt-cloudflare
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
tls:
- hosts:
- whoami.peppermint.cloud
secretName: whoami-peppermint-cloud
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: whoami
port:
number: 80
Hinweise:
- Domain: Passe die Domain in
tls.hostsauf diejenige an, die öffentlich erreichbar ist. - ClusterIssuer: Falls der
cert-managernicht installiert ist oder ein anderer Issuer verwendet werden soll, entferne oder ändere die Annotationcert-manager.io/cluster-issuer.
Durch dieses Deployment wird die whoami-Anwendung über den Traefik-Ingress öffentlich verfügbar und sollte HTTPS-Zertifikate über letsencrypt-cloudflare erhalten, falls alles korrekt eingerichtet ist.
Wir können die Funktionalität des Deployments mit einem einfachen curl-Befehl überprüfen:
curl "https://whoami.peppermint.cloud"
Das Ergebnis sollte dann in etwa wie folgt aussehen:
$ curl "https://whoami.peppermint.cloud"
Hostname: whoami-dxrhk
IP: 127.0.0.1
IP: ::1
IP: 10.42.0.8
IP: fe80::ec63:60ff:fee3:42ad
RemoteAddr: 10.42.0.7:36488
GET / HTTP/1.1
Host: whoami.peppermint.cloud
User-Agent: curl/7.88.1
Accept: */*
Accept-Encoding: gzip
X-Forwarded-For: 10.42.0.1
X-Forwarded-Host: whoami.peppermint.cloud
X-Forwarded-Port: 443
X-Forwarded-Proto: https
X-Forwarded-Server: traefik-57b79cf995-d6ph7
X-Real-Ip: 10.42.0.1
Bei jeder neuen Ausführung von curl ändert sich der Hostname des Containers, der die Anfrage bearbeitet. Das zeigt, dass die Anwendung über mehrere Container repliziert wurde und diese nun auf verschiedenen Hosts verteilt sind. Dadurch wird eine hohe Verfügbarkeit gewährleistet und die Leistung der Anwendung kann durch die Verteilung der Anfragen auf mehrere Instanzen skaliert werden.
Erfolg
Wir haben erfolgreich einen produktiven Kubernetes-Cluster mit BGP-Integration in unserer Proxmox-Infrastruktur eingerichtet. Damit ist die Grundlage für eine hochverfügbare und skalierbare Umgebung geschaffen.
In weiteren Artikeln werden wir uns noch detailliert mit der Einrichtung des Speichers für PersistentVolumeClaims sowie dem HorizontalPodAutoscaling beschäftigen, um die volle Leistungsfähigkeit des Clusters auszuschöpfen.
